The code below offers a walkthrough of Chapter 2: The Computation of Meaning, showing how to replicate all visualizations and data reproduced in that chapter. If you have not yet, be sure to install the litmath and litmathdata R packages, which include the necessary functions and data. Both packages can be installed from Github by opening RStudio and entering the following commands in the console.
devtools::install_github("michaelgavin/litmath@main")
devtools::install_github("michaelgavin/litmathdata@main")
Activate libraries and import data
Starting from a fresh R session with a clear working environment, the first step is always to activate the libraries and import the data.
library(litmath)
library(litmathdata)
data(kwic)
The Keyword-in-Context (kwic) dataset is a matrix that shows word-collocation data for EEBO Phase I texts, 1640 to 1699. This was the data available when the chapter’s analyses were performed. The data includes 32,244 rows, for each keyword in the documents (excluding stopwords and low-frequency terms), and 2,002 columns, for high-frequency context words (still excluding stopwords). The values of each cell in this matrix represent the numbers of times each keyword appears in the context of each context work, within a window of 5 tokens on either side.
Next, define the matrix M by normalizing the Keyword-in-Context data using "positive pointwise mutual information."
M = ppmi(kwic)
Most of the calculations in Chapter 2 are performed over this semantic model. Most visualizations were performed using a function called similarity_map, which identifies the words most semantically similar to a chosen search term (using "cosine similarity") then measures the similarities among those correlate terms and groups them using hierarchical clustering, then maps the results to two dimensions using principal-component analysis.
To recreate Figure 2.6, "Semantic Field of foot in the EEBO Corpus," requires only a single command.
similarity_map(M, "foot")

You’ll notice that graphs produced in R look slightly different from those in the book itself. For publication, I export R graphics as PDF, then edit in Inkscape (an open-source competitor of Adobe Photoshop). I manually edit the fonts and separate out words that overlap too closey to read.
To-recreate Figure 2.7, "Semantic Field of the Composite Vector, square x foot," requires an additional step of pointwise multiplication.
vec = M["foot",] * M["square",]
similarity_map(M, vec)
Before moving on, you should pause to look this over, because this is crucial for understanding why and how semantic models decompose meaning, when "meaning" is conceived dialogically and intertextually. The first line of the code above multiplies the two vectors against each other, thus amplifying the importance of any points of overlap and negating any semantic information that isn’t shared.
The top five context words shared by foot and square are:
sort(vec, decreasing = T)[1:5]
The values of the word frequency counts in these columns, all normalized by PPMI, are multiplied together. The context words foot, length, top, line and steps are all contexts shared with above-average frequency by foot and square. (The word square does not appear on the list because it’s frequent enough to be contained in the 32,224-word vocabulary, but not frequent enough to be among the 2,002 context words used as columns in matrix representation of the model.)
Because PPMI only highlights word frequency values that occur with above-average frequency, all other values are set to zero. This means that all words over-represented in the contexts of foot and square are completely lost, unless they’re shared between the two. To see what’s lost in the composite vector, simply find their differences (that is, subtract them):
sort(M["foot",] - vec, decreasing = T)[1:5]
sort(M["square",] - vec, decreasing = T)[1:5]
Words lost by foot include horse, armed, sole, army, and bare — all terms relating either to war and soldiers (where "foot" and "horse" were synecdoches for infantry and cavalry) or to actual feet as parts of the human body.
This is how conceptual decomposition works. Or, at least, it’s a method for semantic decomposition that seems most intuitive and relevant to me. In the field of information retrieval, a more-common practice is to run a low-dimensional word-embedding model over the corpus, then perform semantic decompositions over the resulting matrix. I use the above method for two reasons: 1) the math is simpler and easier to conceptualize and therefore the results are more reliable and useful in the context of descriptive explication; 2) the results just come out better. The first reason seems obviously right to me. The second emerged only after years of playing around with various models of the EEBO data. I cannot explain why the simplest methods feel most transparent as representations of intertextual meaning, and I wouldn’t know how to measure or prove that they do. I’ve come to trust them nonetheless.
Figures 2.8 to 2.17 are all just variations on the above code.
similarity_map(M, "black")
similarity_map(M, "bladder")
similarity_map(M, "consciousness")
similarity_map(M, "heart")
similarity_map(M, "frogs")
vec = M["frogs",] - M["cats",]
similarity_map(M, vec)
similarity_map(M, "jamaica")
similarity_map(M, "slave")
vec = M["jamaica",] * M["slave",]
similarity_map(M, vec)
vec = M["man",] - (M["husband",] + M["father",] + M["son",])
similarity_map(M, vec)
vec = M["woman",] - (M["wife",] + M["mother",] + M["daughter",])
similarity_map(M, vec)
Conceptual nonstationarity
One issue that I feel did not get sufficient discussion in the book is the notion of "conceptual nonstationarity," a phrase I adapt from quantitative geography. To call something non-stationary is to suggest that it moves around. In geographical data analysis, this refers to things that aren’t distributed equally everywhere. In some places, the average rainfall is really high. In others, it’s quite low. Rain doesn’t just sit equally everywhere. It’s different in different places.
In an analogous way, we can say that concepts are not uniformly distributed over EEBO. If we can subtract the square words from foot and disambiguate its meanings, then that implies the word foot is used differently in different contexts. But the semantic model, based purely on keyword-in-context information gathered over the whole corpus, doesn’t tell us much about the historical contexts that vary among documents. It doesn’t say which documents contribute to foot‘s various meanings. Nor can it alert us, in any straightforward way, to the subtle variations of term’s use by, say, different authors or in texts of different genres, nor can it easily show change over time.
The chapter moves toward analyzing Locke’s Two Treatises (EEBO-TCP: A48901). The method followed in this section of the chapter involves analyzing subsets of the whole corpus using the same 32,244 by 2,002 frame, then comparing each locally produced vector to the whole to see how much it deviates from the norm.
To measure deviance, I use semantic distance, the complement of semantic (cosine) similarity.
semantic_distance = function(x, y) {
sim = cosine_similarity(x, y)
return(1 - sim)
}
Now load the data.
data(locke_A48901)
data(locke_peer_corpus)
Calculate the deviance, 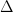
delta = c()
for (i in 1:nrow(locke_A48901)) {
print(i)
vec = semantic_distance(locke_A48901[i,], kwic[i,])
delta = c(delta, vec)
}
names(delta) = rownames(kwic)
as well as the frequency.
freq = rowSums(locke_A48901)
You might notice that I have returned to using kwic, the Keyword-in-Context matrix that has not been normalized by PPMI. This actually enables more accurate comparisons across subsets of the corpus. Because we not comparing different word forms, but always comparing each word to itself, normalization inevitably distorts the measurements, introducing information from elsewhere in the semantic space. When comparing how Locke uses the word "power" to that word as used over the whole, you don’t need or particularly want to normalizes values, because there’s no theoretical reason to believe that the word will have different properties in one context versus the other. PPMI accounts for things like word frequency and filters out noise in the data to compare semantic spaces that are presumptively different. The similarities are what’s interesting across these differences. By contrast, when measuring conceptual nonstationarity, you expect similarities and are looking for those subtle differences. The signal exists in and as the noise.
Semantic deviance in this section is defined for each of the 32,244 context words as the product of semantic distance that separates its use in the local corpus from the whole and the frequency of that word in the local corpus. I refer to this as the conceptual work to local context performs on the word. Conceptual work, 

for each word, 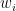
To see the most persistently conventional and deviant words in the corpus, as listed in Table 2.1, take the maxima of word and its inverse:
# Most persistently conventional
sort((1 - delta) * freq, decreasing = T)[1:10]
# Most persistently deviant
sort(delta * freq, decreasing = T)[1:10]
Now, look at a second subcorpus, drawn from documents most semantically similar to Locke’s Two Treatises.
delta_peer = c()
for (i in 1:nrow(locke_peer_corpus)) {
print(i)
vec = semantic_distance(locke_peer_corpus[i,], kwic[i,])
delta_peer = c(delta_peer, vec)
}
names(delta_peer) = rownames(kwic)
delta_locke_to_peer = c()
for (i in 1:nrow(locke_A48901)) {
print(i)
vec = semantic_distance(locke_peer_corpus[i,], locke_A48901[i,])
delta_locke_to_peer = c(delta_locke_to_peer, vec)
}
names(delta_locke_to_peer) = rownames(kwic)
Now, we can find words the most clearly indicate the individual document’s point of contribution to the local corpus. This calculation is admittedly quite strange, and I somewhat fudge its description in the book. The calculation looks like this:

and local conceptual work as:

for each word, 


What makes it strange? If you parse the definition of 
Here’s the calculation:
results = delta - (delta_peer + delta_locke_to_peer)
sort(results * totals, decreasing = T)[1:10]
The semantic maps in Figure 2.18 are calculated as above.
similarity_map(kwic, "children", numResults = 20)
similarity_map(locke_A48901, "children", numResults = 20)
The analysis of the works of Aphra Behn, and of Love Letters between a Nobleman and his Sister within that subcorpus, are calculated in the same way.
data(behn_peer_corpus)
data(behn_A27301)
delta = c()
for (i in 1:nrow(behn_A27301)) {
print(i)
vec = semantic_distance(behn_A27301[i,], kwic[i,])
delta = c(delta, vec)
}
names(delta) = rownames(kwic)
totals = rowSums(behn_A27301)
sort(delta * totals, decreasing = T)[1:10]
# Table 2.2
# Most persistently conventional (Not in Table 2.2)
sort((1 - delta) * totals, decreasing = T)[1:10]
# Most persistently deviant
sort(delta * totals, decreasing = T)[1:10]
# Compare peer corpus to EEBO, 1640-1699
delta_peer = c()
for (i in 1:nrow(behn_peer_corpus)) {
print(i)
vec = semantic_distance(behn_peer_corpus[i,], kwic[i,])
delta_peer = c(delta_peer, vec)
}
names(delta_peer) = rownames(kwic)
# All works vs. EEBO:
sort(delta_peer * rowSums(behn_peer_corpus), decreasing = T)[1:10]
delta_behn_to_peer = c()
for (i in 1:nrow(behn_A27301)) {
print(i)
vec = semantic_distance(behn_peer_corpus[i,], behn_A27301[i,])
delta_behn_to_peer = c(delta_behn_to_peer, vec)
}
names(delta_behn_to_peer) = rownames(kwic)
# Love Letters vs. peer corpus
# Note this is mislabeled in Table 2.2
sort(delta_behn_to_peer * totals, decreasing = T)[1:10]
# Most persistently deviant, triangulated by peer corpus
# Note that this triangulation returns words that violate triangle inequality;
# thus they are the words for which the contextual subcorpus provides a
# conceptual shortcut
vec = delta - (delta_peer + delta_behn_to_peer)
sort(vec * totals, decreasing = T)[1:10]
# Figure 2.19
similarity_map(behn_peer_corpus, "vows", numResults = 15)
similarity_map(behn_peer_corpus, "devil", numResults = 15)
Conceptual ‘change’ as conceptual nonstationarity
The last couple of examples measure conceptual change over time. It’s important to understand that there really isn’t any such thing as "change over time" and that what we conventionally think of as "history" is an extremely powerful ideological construct. The only wholly true thought we can hold about the past is that it isn’t happening now. Everything else is an idea we impose on the things we see and think about now.
This is true of everything, not just corpora, but it’s especially salient in corpus analysis where measuring change over time just means lumping the documents together by date then sorting those lumps. Because the corpus I’m working with in this chapter is labelled 1640 to 1699, I create 60 lumps, and for each I measure the conceptual work of the subcorpus.
The calculations then are similar to those above, but with two minor differenences. Rather than measure delta as deviance, I measure it as similarity. It doesn’t really make any difference, because semantic distance and similarity are just complements of each other. But using similarity instead of distance means that the most interesting years are peaks in the graph, rather than valleys, and that just makes more sense graphically. And rather than use raw term frequency, which can be strongly influenced by a single large book, I measure the document frequency for each word in each year.
For lack of a better word, I describe the conceptual work performed by time as topicality, 


where 

To recreate figures 2.20 and 2.21, download the data and run the following.
data(conceptual_change)
plot(conceptual_change["oates",], type = "l")
plot(conceptual_change["management",], type = "l")
And figure 2.22 is just a similarity map, calculated as above, but over the matrix of temporality measurements.
similarity_map(conceptual_change, "oates", numResults = 20)
similarity_map(conceptual_change, "management", numResults = 20)
Conclusion
Measurements of conceptual nonstationarity are often highly revealing about how words are situated historically in the corpus, and as I mention in the book it’s possible to perform all kinds of comparisons. In fact, if you have followed along with the analysis above and you’re at all familiar with late 17th-century English print, you should take some time to play with the data.
Many years ago I wrote a dissertation about the history of English-language literary criticism. A major figure was John Dryden, a poet and playwright who was quite unusual for his time, and who devoted a great deal of his own work and thought toward cultivating himself as a representative figure of English letters — a leader among poets of "the present Age," as he’d called it. He’d have been pleased, I think, to see how his name appears in the semantic model:
similarity_map(M, "dryden)

But he was plagued throughout his life by "criticks," that is, by people more like trolls and haters than proper judges of poetry. He felt continually beset by fools and dullards, and indeed the time of his career was also a time when authors increasingly wrote attacks on each others’ work.
C = conceptual_change
similarity_map(C, "dryden")

Over a standard semantic model, Dryden is associated with the great authors of his time, of Shakespeare’s, and of the classics. His name is synonymous with books and poetry and panegyric. But if you consider how his name is situated within time, and ask not what concepts his name is most similar to, but which concepts emerged in the public sphere at the same time as his writing self, then dryden‘s surrounded by nonsense and blockheads.
As I say in the book…
The model works because the theory behind it is true.
FINAL NOTE: Once a suitable vocabulary of keywords and context terms is identified, any corpus can be represented as a third-order array that allows for complex reorganization and sub-setting according to bibliographical or lexical metadata. However, semantic modeling in this way is not computationally efficient, and the datasets generated take up as much memory as the EEBO-TCP corpus itself. For this reason, it’s not easy to share the files, and the scripts take some time to run and can be difficult to set up. Readers of this walkthrough who’d like to perform analyses from scratch or devise their own experiments for measuring conceptual nonstationarity should contact the author, Michael Gavin, at his publicly available university email address.